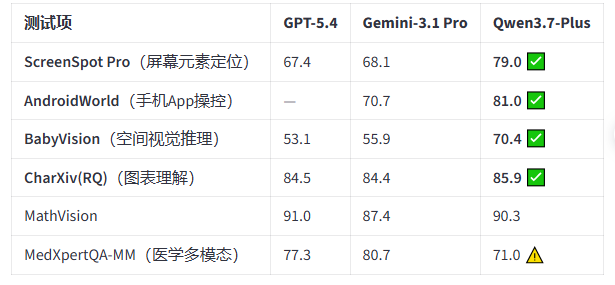
“一个模型,能看、能想、能写代码、能行动。”阿里官方介绍,Qwen3.7-Plus构建的Hybrid-Agent系统,曾连续稳定运行11小时以上,自动完成一款英语单词学习App的完整研发闭环,还自主复刻了一款股票行情应用。模型屏幕理解得分79,超过GPT-5.4和Gemini-3.1 Pro。
MiniMax M3模型昨日刚炸场,阿里千问又发布了一个强到可怕的新“怪物”。
6月2日,阿里云通义千问团队在X平台正式宣布发布Qwen3.7-Plus。这是一个多模态Agent模型,官方表述是“将视觉与语言统一为一体化智能体基座”。
团队用一句话来概括了它的产品定位:“一个模型,能看、能想、能写代码、能行动。”
用Qwen3.7-Plus做App、复刻股票应用不在话下。千问官方博客披露,基于Qwen3.7-Plus构建的Hybrid-Agent系统,曾连续稳定运行11小时以上,自动完成一款英语单词学习App的完整研发闭环。Hybrid-Agent系统还自主完成了macOS原生Stocks股市应用的高保真复刻。而模型屏幕理解得分79,也超过GPT-5.4和Gemini-3.1 Pro。
而千问这次发布的时间点颇为微妙。就在前一天,MiniMax刚刚推出新一代旗舰开源模型M3,宣称同时实现顶尖编程能力、1M超长上下文与原生多模态。两家在同一周内密集发布,国内大模型开源竞赛愈发白热化。
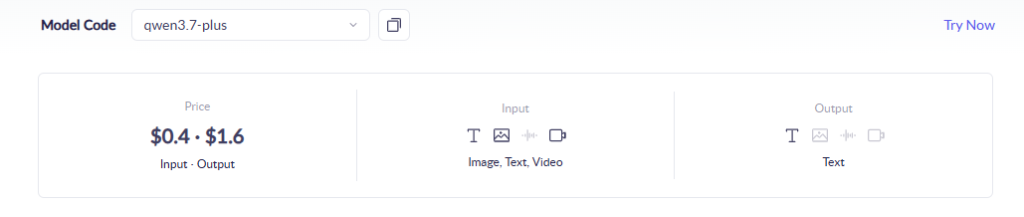
Qwen3.7-Plus的定价为:输入$0.4/百万token,输出$1.6/百万token。
“看、想、写、做”打通了:一个模型看屏幕、写代码、操作App
Qwen3.7-Plus的核心看点,是把视觉理解和任务执行真正连在了一起。
官方博客描述,这个模型能"感知真实世界场景、读取屏幕并操作GUI、基于视觉参考生成代码、端到端导航移动应用",并在单一智能体循环中无缝融合GUI与CLI交互。
这里有两个关键词:GUI和CLI。GUI就是图形界面,比如网页按钮、手机App菜单、桌面软件窗口。CLI就是命令行,比如工程师用来安装依赖、运行测试、部署服务的黑色窗口。
简单说:它不只是"看懂图片",而是能看懂你的手机屏幕或电脑界面,然后自己点击、输入、跳转,把任务做完。
比如,它可以读取屏幕,理解手机App或网页界面里哪个按钮该点;也可以看一张设计图,然后生成SVG、网页或前端原型;还可以在命令行里跑代码、看报错、再改代码。

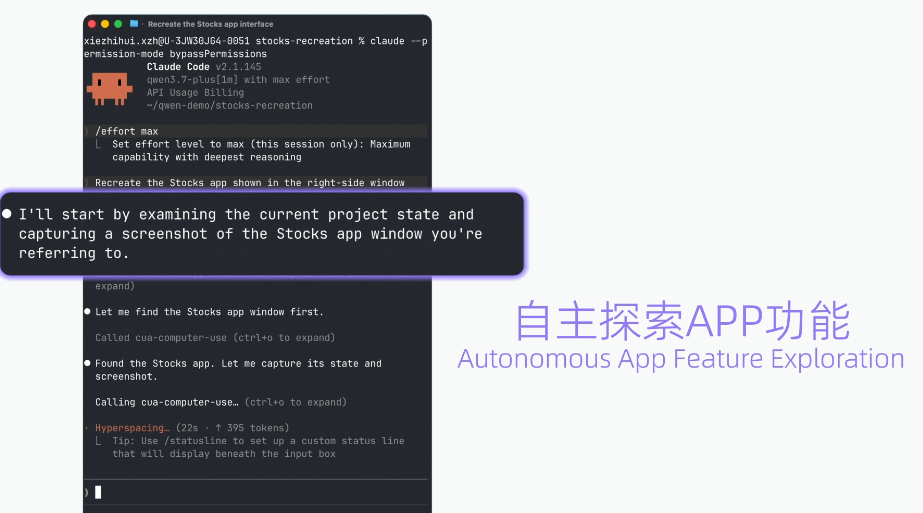
连续跑11小时,开发一个英语单词学习App
关于Qwen3.7-Plus具体能做什么:官方给了几个很产品化的演示。
Qwen官方博客称,基于Qwen3.7-Plus构建的Hybrid-Agent系统,连续稳定运行11小时以上,自动完成一款英语单词学习App的研发闭环。
细节包括:生成代码超过10000行,触发Agent调用超过1000次,覆盖需求文档生成、代码自动编写、自动化安装部署、测试用例创建、GUI自动化测试、多场景并行测试、产品说明自动更新和版本迭代。
这个案例的关键点不在于“写了多少代码”,而在于链路够长。一个真实软件任务往往不是一次生成代码就结束,还要安装、运行、测试、改Bug、再验证。官方演示想强调的正是这种长流程能力。

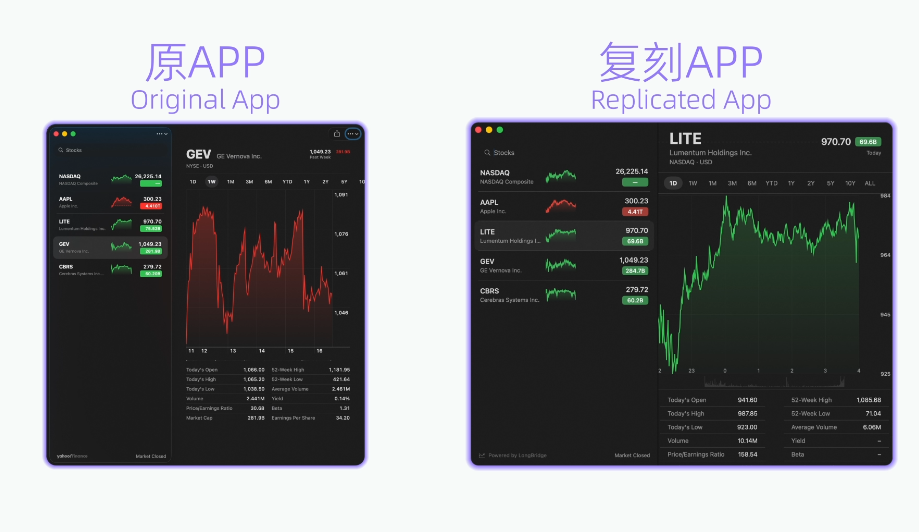
复刻炒股APP,还接入真实行情API
另一个官方案例是,直接做一个炒股APP。
Qwen官方博客称,Hybrid-Agent系统自主完成了macOS原生Stocks股市应用的高保真复刻。流程包括:交互原生应用并理解UI布局和功能细节,基于交互记录生成SwiftUI源码,接入LongBridge真实行情API获取实时市场数据,自动编译构建并启动复刻应用。
模型自主执行了10项功能验证测试,内容包括实时行情加载、股票选择与切换、多周期视图切换、搜索过滤和详细数据面板展示等,且全部通过。
这个演示更直观:模型不是只生成一个静态页面,而是要理解行情App的结构、数据源和交互逻辑,再把它做成一个可以运行的桌面应用。

看图写代码:图像/视频转SVG,也能生成网页原型
Qwen官方博客称,Qwen3.7-Plus可以将图像、视频、UI截图和设计参考转化为可执行代码,覆盖SVG复现到完整网页生成。
在图像/视频转SVG任务中,模型需要识别几何结构、颜色、布局、层级关系和动态变化,再用代码表达出来。对于图标、插画、动效、图形设计和信息可视化,这类能力的产品价值在于:把“看见的参考图”变成“可编辑的代码资产”。
在网页设计任务中,模型不仅要复现页面风格,还要组织布局、写前端代码、处理交互逻辑,并把多模态素材整合进最终页面。
同时,Qwen3.7-Plus可以作为视觉Agent,把视觉理解和工具使用结合起来,解决找不同、补图块、华容道、走迷宫、拼拼图等任务。
这里的流程不是“看一眼给答案”。模型会先理解图像结构和约束,再把视觉问题转成可计算的问题表示,然后自主编写并执行代码进行求解、搜索或验证。
跑分怎么看:屏幕理解跑赢GPT-5.4,但不是所有项目都第一
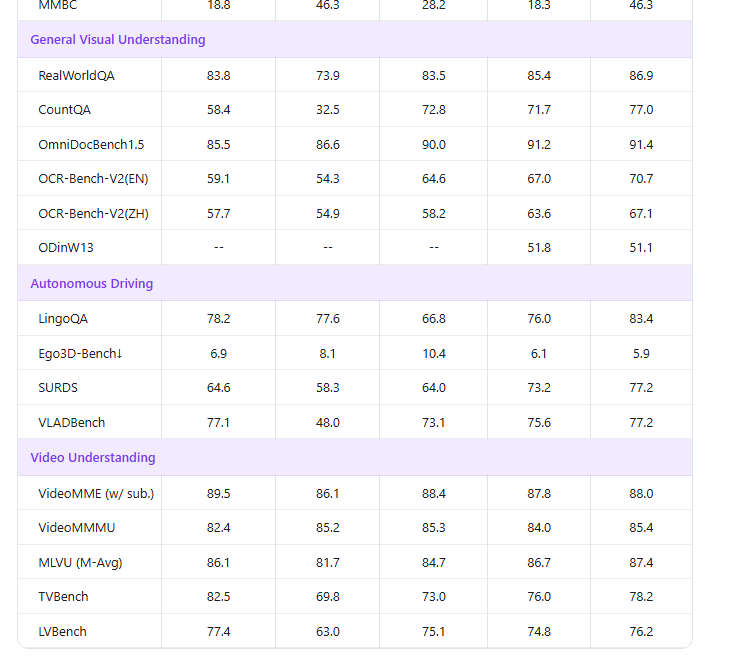
在多模态基准测试上,Qwen3.7-Plus有几个数字值得关注:
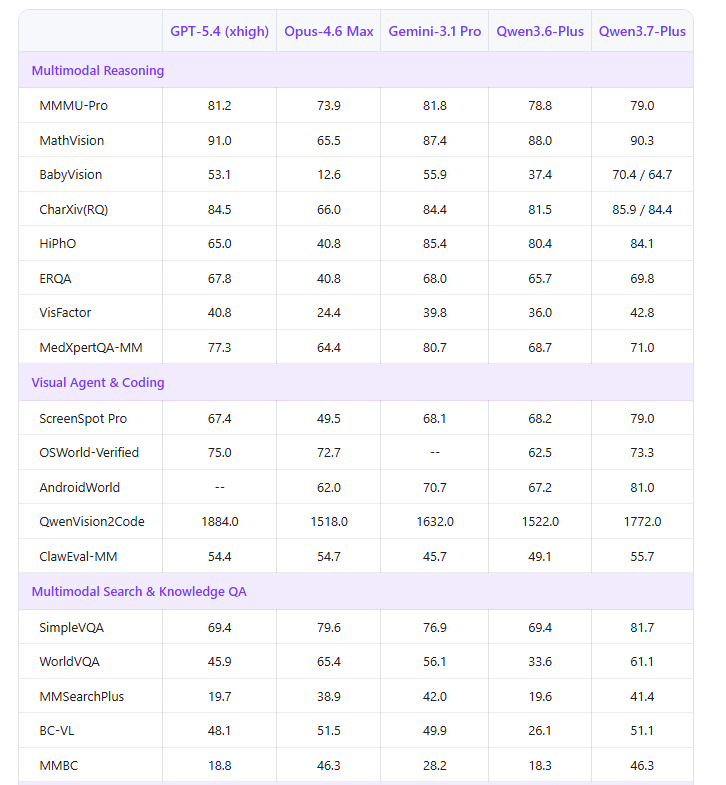
屏幕理解和移动端操控:ScreenSpot Pro得分79.0,高于GPT-5.4(67.4)和Gemini 3.1 Pro(68.1);AndroidWorld得分81.0,同样超过Gemini 3.1 Pro(70.7)和Opus-4.6 Max(62.0)。
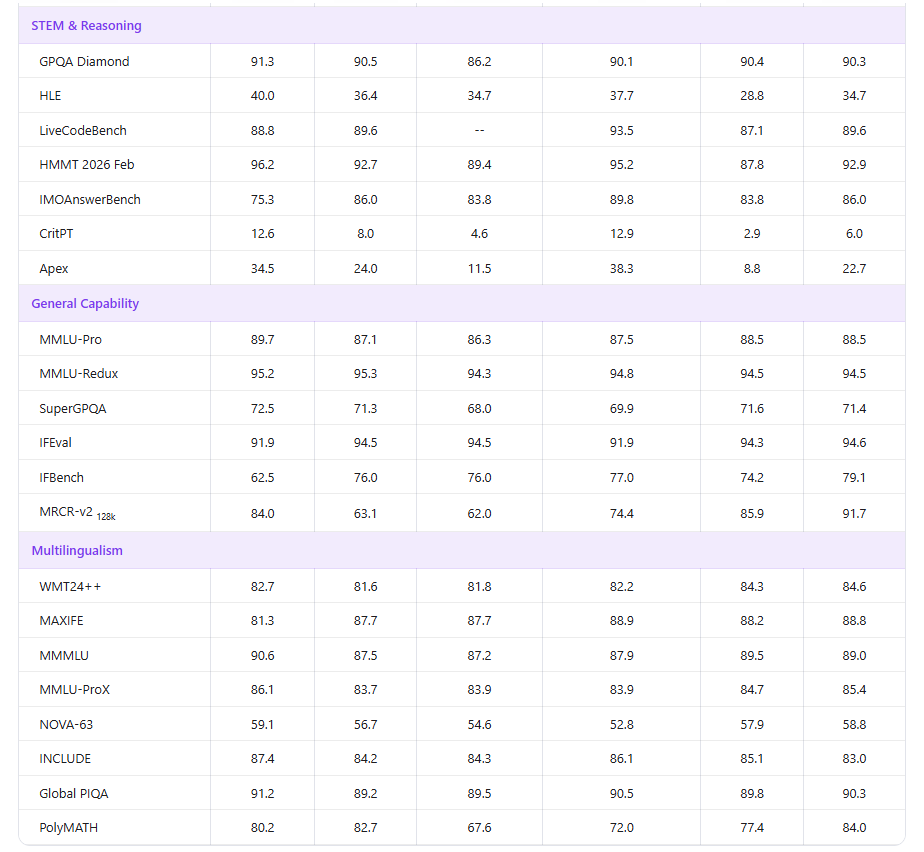
数学视觉推理:MathVision得分90.3,接近GPT-5.4的91.0,超过Gemini 3.1 Pro的87.4。
搜索增强视觉问答:SimpleVQA得分81.7,WorldVQA得分61.1,在这一赛道上与Opus-4.6 Max基本持平。
图表识别:CharXiv(RQ)得分85.9,为所有参与对比模型中最高。
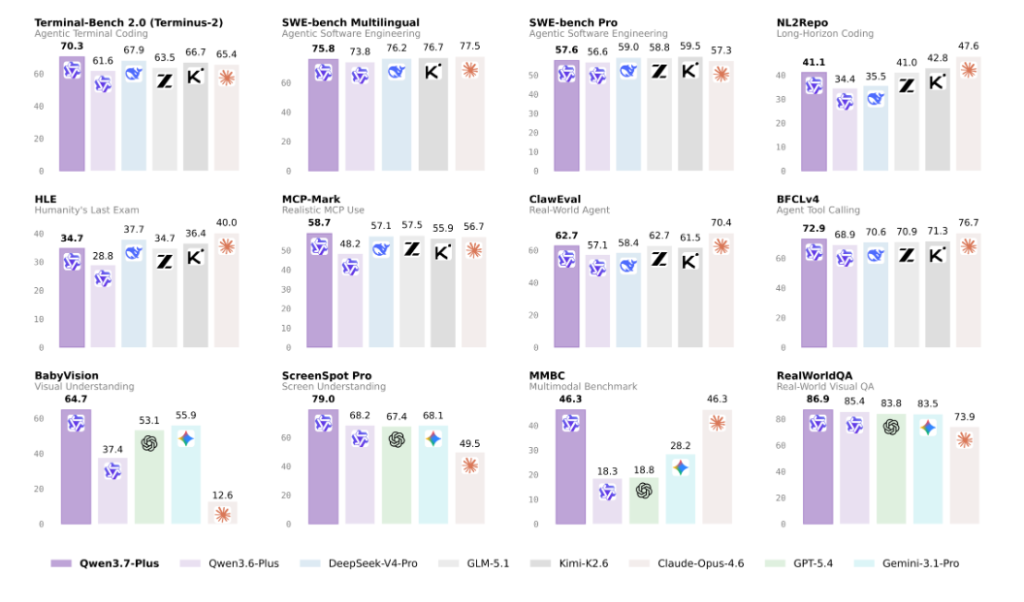
纯文本能力方面,官方表示Qwen3.7-Plus"整体接近Max级别模型"。
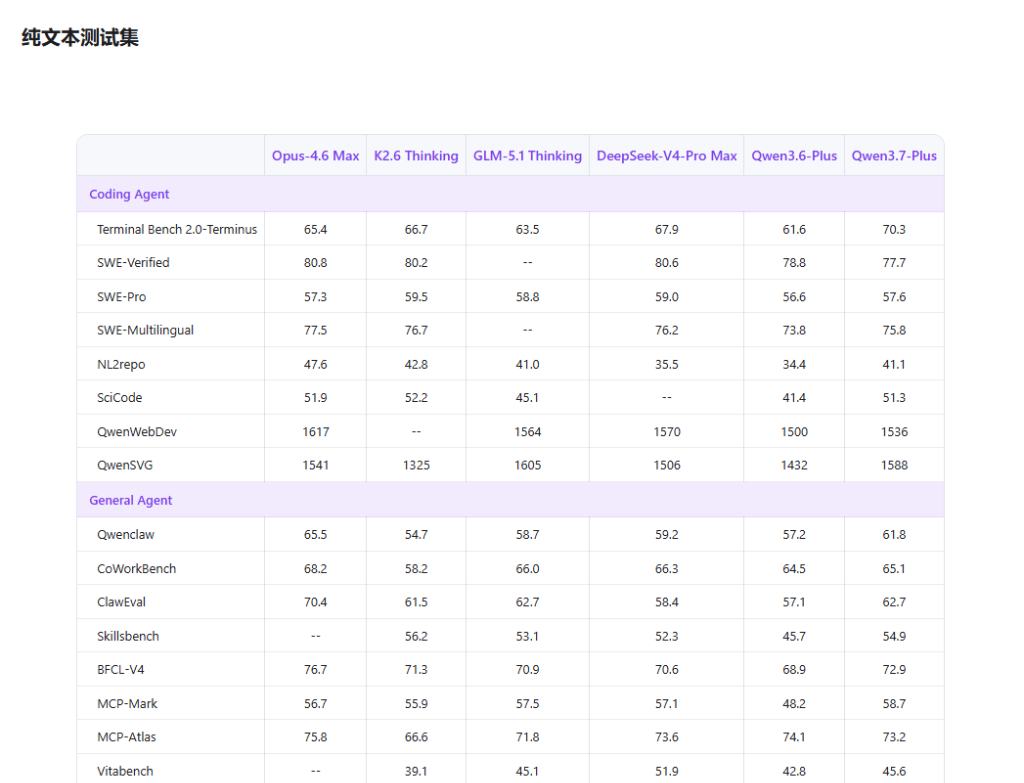
在Terminal Bench 2.0上得分70.3,超过Opus-4.6 Max(65.4)、K2.6 Thinking(66.7)和DeepSeek-V4-Pro Max(67.9)。
在Deep-Planning(复杂多步规划)上得分62.3,同样领先同级别模型。
不过也有弱项。
在SWE-Verified(真实软件工程任务)上得分77.7,低于Opus-4.6 Max(80.8)和DeepSeek-V4-Pro Max(80.6);在HLE(极难推理)上得分34.7,低于GPT-5.4(40.0)。
网友怎么看?
Qwen官方账号@Alibaba_Qwen于6月2日凌晨1:54发布公告,配合Demo视频展示了多模态混合Agent的操作过程。截至发文,该推文阅读量已达20万。
X网友表示,Qwen3.7-Plus模型不仅要面对各种屏幕,还要操作各类工具,并应对杂乱的工作流程。
还有网友表示,Qwen这次的打法很清晰,就是往Agent和GUI操控上押注,这个方向现在是对的。
多个网友表示,Qwen将“看、想、写、做”集成于一个模型,实在太方便了。简直是“集成了一套员工系统!”

相关评论中,不少技术用户关注的重点集中在两个方向:
一是ScreenSpot Pro的79分——这被不少人认为是"GUI Agent能否真正商用"的关键门槛指标,Qwen3.7-Plus目前是参测模型中的最高分;
二是Kernel Bench L3的98%——这个指标衡量的是模型优化GPU计算核心的能力,98%意味着几乎所有问题都能产出超越PyTorch默认编译器的方案。有用户指出,这个方向以前几乎是专业工程师的"禁区"。
与MiniMax M3的横向对比
两款模型几乎同期发布,定位有所不同。
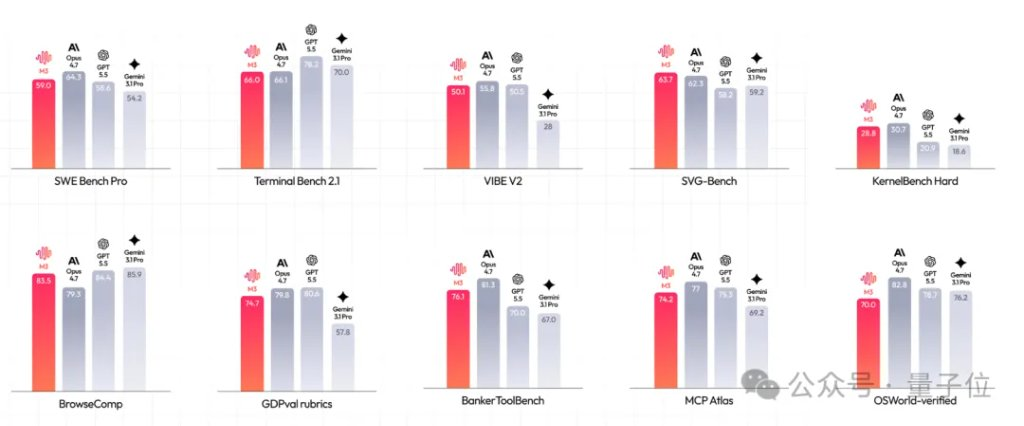
MiniMax M3主打开源,技术报告和模型权重承诺在10天内公开,核心差异化是1M超长上下文(M3在1M上下文下每token计算量只有上代的1/20)和极强的长线程Agent能力(147次benchmark提交、1959次工具调用完成FP8矩阵乘优化)。
MiniMax团队让M3独立复现一篇ICLR 2025获奖论文。该任务需要看懂图文、曲线、数据和公式,也需要长上下文装入论文、代码和实验日志,还需要编程和Agent能力完成复现。M3自主运行接近12小时,最终跑通核心实验。
Qwen3.7-Plus目前仅提供API调用,不开源权重,核心差异化是多模态与GUI操作能力的深度整合,以及对主流开发框架的即插即用兼容性。
两者在编程Agent能力上存在直接竞争,但侧重点不同:M3更强调长上下文下的自主科研和代码优化能力,Qwen3.7-Plus更强调视觉感知与界面操作的端到端闭环。
Comments